Pandas기본 명령어 및 기본세팅
import pandas as pdpandas를 불러오고, pd로 저장해 준다.
data = pd.read_csv('https://raw.githubusercontent.com/DSNote/taling_data/main/insurance.csv')csv 파일을 불러와서 data라는 변수에 저장해 준다.

data값은 위와 같은데 너무 긴 것을 알 수 있다. 그래서 사용하는 것이 head(), tail() 함수이다.
data.head()
head() 함수를 통해 상위 5개만 불러올 수 도 있고
data.tail()
tail()이라는 함수를 통해서 하위 5개만 불러올 수 있다.
data.info()info() 함수를 통해서는 data의 정보를 알 수 있다. 총 6개의 칼럼을 가진 것을 알 수 있다.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1338 entries, 0 to 1337
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 age 1338 non-null int64
1 gender 1338 non-null int64
2 bmi 1338 non-null float64
3 children 1338 non-null int64
4 smoker 1338 non-null int64
5 charges 1338 non-null float64
dtypes: float64(2), int64(4)
memory usage: 62.8 KBdata.describe()describe 함수를 통해서 data의 다양한 값을 볼 수 있다.

훈련세트와 테스트 세트 나누기
X = data.drop('charges', axis=1)
y = data['charges']X는 charge라는 칼럼을 제외한 부분을 변수로 입력해 준 것이고, y는 charge라는 칼럼 부분만 입력한 변수이다.
X, y는 X는 칼럼이 많으므로 대문자로 사용하고, y는 칼럼이 적으므로 소문자로 사용한다.


from sklearn.model_selection import train_test_splitsklearn의 model_selection 패키지에서 train_test_split 모듈을 임포트해온다.
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size= 0.2, random_state=100)각각 train, test 세트를 나눠준다. test_size=0.2라는 것은 train 8 : test:2 비율로 나눠준다는 것이고, random_state=100이라는 말은 random으로 계속 돌리면 타인과 공유할 때 값이 달라질 수 있으므로 임의의 값을 주는 것이다.
from sklearn.linear_model import LinearRegressionLinearRegression을 구현할 것이므로 sklearn에서 위의 패키지와 모듈을 불러온다.
lr = LinearRegression()함수를 변수에 할당해 준다.
lr.fit(X_train, y_train)트레이닝 세트를 훈련시켜 모델을 만들어 준다.
pred = lr.predict(X_test)X_test의 예측값을 pred라는 변수에 할당해 준다.
result = pd.DataFrame({'actual':y_test, 'pred':pred})그리고 실제값을 actual로 pred를 예측값으로 놓고 result 변수에 DataFrame형태로 저장해 준다.
데이터를 시각화하기
import matplotlib.pyplot as plt
import seaborn as snsmatplotlib과 seaborn은 데이터 시각화 패키지임으로 둘 다 불러온다.
plt.figure(figsize=(5,5))
sns.scatterplot(x='actual', y='pred', data=result)x값은 실제값으로, y값을 예측값으로 넣고, result값을 그래프로 표현해 준다. plt를 통해서는 그래프의 크기 비율을 정해준다.

그래프를 보면 선형으로 직선 그래프가 아니라 그래프의 중간 부분을 보면 실제값보다 예측값이 높은 것을 확인할 수 있다.
모델 평가하기
from sklearn.metrics import mean_squared_error평가하기 위해서 RMSE라는 지표를 사용하기 위해 위의 패키지를 가져온다.
평가지표는 MAE, MSE, RMSE가 있는데 MAE는 Mean Absolute Error로 MSE는 Mean Squared Error로 각각 실제값과 예측값의 절댓값의 차이, 제곱의 차이값으로 비교된다.
자연스럽게 오차가 적으면 더 좋은 모델이라는 것을 짐작해 볼 수 있다.

MSE를 구할 수 있는데 , squared를 False로 하면 RSME를 구할 수 있다.
lr.score(X_train, y_train)lr.score를 통해서 트레이닝 세트의 점수를 확인할 수도 있다.
lr.coef_
lr.intercept_위의 명령어를 통해 기울기 값과 상수값을 구할 수 있다.

각각의 계수와 함께 첫째 행에 값을 넣어서 구하면
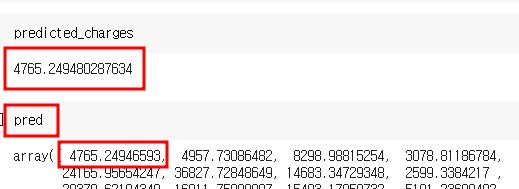
실제의 예측값의 값과 동일해진다. 출력된 값의 소수점은 반올림여부에 따라 조금 달라질 수는 있다.
이외에도 여러 회귀가 있다.
from sklearn.linear_model import Ridge선형 회귀모델에서 L2정규화를 적용한 모델로 오버피팅(과적합)을 억제하는 효과가 있다.
from sklearn.linear_model import Lasso선형 모델에서 L1정규화를 적용한 모델로 피처 셀렉션 및 오버피팅을 억제하는 효과가 있다.
from sklearn.linear_model import ElasticNet릿지 회귀와 라쏘 회귀의 단점을 절충시킨 모델이다.

