K-최근접 이웃(KNN) 모델은 거리 기반 모델로 종속변수가 범주형이며, 개수가 3개 이상인 다중 분류(Multicalssification)를 다룬다. 직관적이고 간단하며, 선형관계를 가정 안 해도 되지만, 데이터가 커질수록 상당히 느려질 수 있고, 아웃라이어(이상치)에 취약하다.
문제 정의
각각의 성분에 따라서 와인등급이 어떻게 되는지 예측하기
데이터 확인하기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
file_url = 'https://media.githubusercontent.com/media/musthave-ML10/data_source/main/wine.csv'
data=pd.read_csv(file_url)필수 라이브러리를 한번에 불러오고, csv파일도 불러온다..
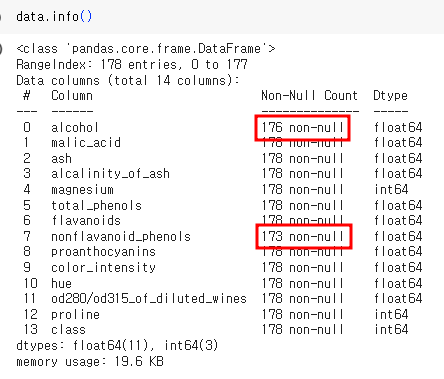
alchohol과 nonflavanoid_pheols가 결측치가 있는 것을 확인할 수 있다.
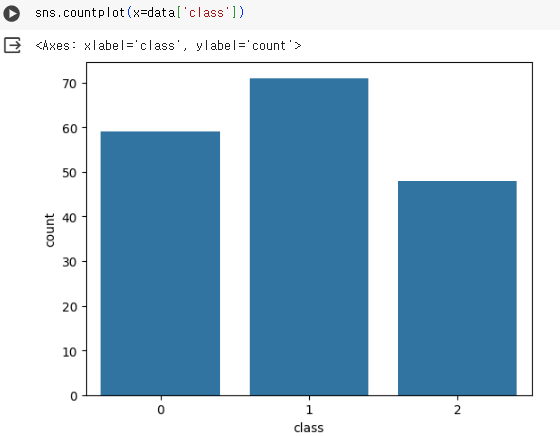
countplot을 통하여 클래스 별로 개수가 몇 개 있는지 알 수 있다.
결측치 처리하기

isna함수를 통해서 결측치가 있는 것을 확인할 수 있다.

isna 함수 뒤에 mean함수를 통해서 어느 정도 결측치가 있는지 확인할 수 있다. alchohol과 nonflavanoid_pheols은 각각 1.1%, 2.8% 정도의 결측치를 갖는다.
결측치를 보고 결측치를 어떻게 할지 정해야한다.
- 결측치가 있는 행을 제거하기
결측치 비중이 매우 낮아야 하고, 데이터 크기도 충분히 커야 함
data.dropna()
#결측치 행 제거
data = data.dropna()
data.dropna(inplace=True)
#데이터 프레임까지 바꿔버림
data.dropna(subset=['alcohol'])
#특정 행만 제거할 수 있음-변수를 제거하기
신중하게 판단
data.drop(['alchohol','nonflavanoid_phenols'], axis=1)- 결측값 채우기: fillna()
평균값으로 채울 수 있지만 이상치의 영향을 받을 수 있으므로, 중윗값을 사용할 수 있다.
data.fillna(data.median(), inplace=True)스케일링 적용하기
| 표준화 스케일링 | 평균 0, 표준편차 1 데이터를 고르게 하고 싶을 때 사용, outlier의 영향을 받음, 기존 분포 형태가 사라지고 정규분포를 따르는 결과물을 가져옴 |
| 로버스트 스케일링 | 데이터에 아웃라이어의 영향이 크고 피하고 싶을 때, 변환된 데이터의 범위는 다른 2개 보다 넓게 나타남 |
| 최소-최대 스케일링 | 데이터 분포의 특성을 최대한 그대로 유지하고 싶을 경우 |
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler스케일링을 적용할 때, 종속변수를 제외해야 하고, 스케일링 전에 훈련 셋과 시험 셋을 나눠야 한다.
from sklearn.model_selection import train_test_split
X= data.drop('class',axis=1)
y = data['class']
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2, random_state=100)훈련셋과 시험셋을 나눠준다.
mm_scaler= MinMaxScaler()
mm_scaler.fit(X_train)MinMaxScaler를 통해 X_train을 학습시킨다.
두 가지 방법 중 하나를 골라 학습 데이터와 테스트 데이터를 트랜스폼 해준다.
X_train_scaled = mm_scaler.transform(X_train)
X_test_scaled = mm_scaler.transform(X_test)X_train_scaled = mm_scaler.fit_transform(X_train)
X_test_scaled= mm_scaler.transform(X_test)from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(X_train_scaled,y_train)
pred = knn.predict(X_test_scaled)
from sklearn.metrics import accuracy_score
accuracy_score(y_test,pred)
0.8888888888888888모델링 및 예측/평가를 해준다.
하이퍼파라미터 튜닝
scores = []
for i in range(1,21):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train_scaled,y_train)
pred = knn.predict(X_test_scaled)
acc = accuracy_score(y_test,pred)
scores.append(acc)
scores를 통해 n_neighbors가 언제 최적의 값인지 살펴본다. 지금은 개수가 얼마 없지만 갯수가 많아지면 어디가 최대인지 확인하기가 어렵다. 그래서 그래프로 확인해 보겠다.
sns.lineplot(x=range(1,21), y=scores)
plt.xticks(range(1,21))
plt.show()
그래프로 확인했을 때 13 이후에는 성능이 좋아지지 않는다. 따라서 13이 최적의 매개변수가 된다.
만약 이웃을 고려할 때 동점일 경우가 생길 수 있는데, 고려할 이웃수를 항상 홀수로 유지하거나, 가중치를 주어서 해결할 수 있다.


