XGBoost 이후 나온 최신 부스팅 모델로, 캐글에서 좋은 퍼포먼스를 많이 보여주어 그 성능을 인정받았으며, 리프 중심 트리 분할 방식을 사용한다. XGBoost보다 빠르고, 높은 정확도를 보이며, 예측에 영향을 미치는 변수의 중요도를 확인할 수 있다. 변수 종류가 많고, 데이터가 클수록 상대적으로 뛰어난 성능을 보여준다. XGBoost와 마찬가지로 복잡한 모델인 만큼, 해석의 어려움이 있고, 하이퍼파라미터 튜닝이 까다롭다.
문제정의
데이터셋을 활용하여 이상거래를 탐지한다.
라이브러리 및 데이터 불러오고, 확인하기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
file_url='https://media.githubusercontent.com/media/musthave-ML10/data_source/main/fraud.csv'
data = pd.read_csv(file_url)라이브러리 임포트
data.info(show_counts=True)<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1852394 entries, 0 to 1852393
Data columns (total 22 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 trans_date_trans_time 1852394 non-null object
1 cc_num 1852394 non-null int64
2 merchant 1852394 non-null object
3 category 1852394 non-null object
4 amt 1852394 non-null float64
5 first 1852394 non-null object
6 last 1852394 non-null object
7 gender 1852394 non-null object
8 street 1852394 non-null object
9 city 1852394 non-null object
10 state 1852394 non-null object
11 zip 1852394 non-null int64
12 lat 1852394 non-null float64
13 long 1852394 non-null float64
14 city_pop 1852394 non-null int64
15 job 1852394 non-null object
16 dob 1852394 non-null object
17 trans_num 1852394 non-null object
18 unix_time 1852394 non-null int64
19 merch_lat 1852394 non-null float64
20 merch_long 1852394 non-null float64
21 is_fraud 1852394 non-null int64
dtypes: float64(5), int64(5), object(12)
memory usage: 310.9+ MB데이터 확인
trans_date_trans_time:거래시간-> object이므로 타입을 바꿔줄 필요가 있음
cc_num: 카드 번호
merchant: 거래 상점
category:거래 상점의 범주
amt:거래 금액
first/last:이름
gender:성별
street/state/zip:고객 거주지 정보
lat/long 고객 주소에 대한 위도 및 경도
city_pop: 고객의 zipcode에 속하는 인구수
job: 직업
dob: 생년월일
trans_num: 거래번호
unix_time: 거래 시간유닉스타임스탬프형식
merch_lat/merch_long:상점 위치에 대한 위도 및 경도
is_fraud:사기거래 여부종속변수
round(data.describe(),2)
통계치를 확인
amt와 city_pop은 이상치를 보이고 있는데, 가격이나 인구수는 얼마든지 변할 수 있음으로 처리하지 않음
is_fraud의 평균이 0.01이므로 1%밖에 되지 않는다. 0에 치우는 비대칭 데이터임으로 하면서 오버샘플링을 해주어서 예측 정확도를 향상할 수 있다.
전처리: 데이터 클리닝
data.drop(['first','last','street','city','state','zip','trans_num','unix_time','job','merchant'], axis=1, inplace=True)필요 없는 변수 제외사기에별로영향을미치지않는것
이름, 도시, 길, 주, 우편번호 이런 것은 영향이 없을 것으로 예상되고, trans_num, unix_time도 trans_date_trans_time을 사용하면 됨으로 필요 없어 보인다.
job과 merchant도 제외시키겠다. job은 갯수가 너무 많아 더미변수로 사용하기 어렵고, 상점 별로 이상거래가 높을 수 있지만, category 변수의 사용을 통해 대체해 보겠다.
data['trans_date_trans_time'] = pd.to_datetime(data['trans_date_trans_time'])데이터 형식을 바꿔준다.
전처리: 피처 엔지니어링
결제금액
갑자기 결제를 많이 하면 이상치로 의심해 볼 수 있다.
amt_info = data.groupby('cc_num').agg(['mean','std'])['amt'].reset_index()cc_num을 기준으로 amt에 대한 평균과 표준편차를 구해준다.
data = data.merge(amt_info,on='cc_num', how='left')cc_num을 키값으로 해서 기존 데이터에 left join을 해준다.
data['amt_z_score'] = (data['amt']-data['mean'])/data['std']data.drop(['mean','std'], axis=1, inplace=True)z_score를 구하고, 평균과 표준편차를 지워준다.
범주
사람마다 많이 쓰는 범주가 있다.
category_info = data.groupby(['cc_num','category']).agg(['mean','std'])['amt'].reset_index()data = data.merge(category_info, on=['cc_num','category'], how='left')data['cat_z_score'] = (data['amt']-data['mean'])/data['std']
data.drop(['mean','std'], axis=1, inplace=True)동일한 방식으로 진행해 준다.
거리
평상시에 쓰는 거리보다 훨씬 먼 거리라면 의심해 볼 수 있다.
import geopy.distancedata['merch_coord'] = pd.Series(zip(data['merch_lat'], data['merch_long'])) #위도, 경도 통합
data['cust_coord'] = pd.Series(zip(data['lat'],data['long']))#위도, 경도 통합data['distance'] = data.apply(lambda x: geopy.distance.distance(x['merch_coord'], x['cust_coord']).km, axis=1)# 1. 거리 통계량 계산
distance_info = data.groupby('cc_num').agg(['mean', 'std'])['distance'].reset_index()
# 2. 거리 통계량 병합
data = data.merge(distance_info, on='cc_num', how='left')
# 3. 거리 Z-점수 계산
data['distance_z_score'] = (data['distance'] - data['mean']) / data['std']
# 4. 결과 확인
data.head()나이
data['age'] = 2024-pd.to_datetime(data['dob']).dt.year불필요한 변수 제거 및 더미변수
data.drop(['cc_num', 'lat','long','merch_lat','merch_long', 'dob', 'merch_coord', 'cust_coord'], axis=1, inplace=True)
data= pd.get_dummies(data, columns=['category','gender'], drop_first=True)data.set_index('trans_date_trans_time', inplace=True)불필요한 변수를 제거하고 더미변수를 만든 후 인덱스를 정해준다.
모델링 및 평가하기
train = data[data.index < '2020-07-01']
test = data[data.index >= '2020-07-01']날짜를 기준으로 훈련 셋과 시험 셋을 나눈다.
len(test)/len(data)
0.2837738623640543약 28% 정도가 시험셋임을 확인할 수 있다.
X_train = train.drop('is_fraud', axis=1)
X_test = test.drop('is_fraud', axis=1)
y_train = train['is_fraud']
y_test = test['is_fraud']훈련 셋과 시험 셋을 만든다.
pip install lightgbm==3.2.1lightgbm은 4.0 이상은 많이 바뀌었으므로, 이번 실습에서는 3.2.1로 설치해 주겠다.
import lightgbm as lgbmodel_1 = lgb.LGBMClassifier(random_state =100)
model_1.fit(X_train, y_train)
pred_1 = model_1.predict(X_test)모델을 만들어주고, 훈련시킨 후, 예측변수를 만들어준다.
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, roc_auc_score이번에는 roc_auc_score도 불러와 주겠다.
accuracy_score(y_test, pred_1)0.9970665504954714print(confusion_matrix(y_test,pred_1))[[522892 757]
[ 785 1227]]print(classification_report(y_test, pred_1)) precision recall f1-score support
0 1.00 1.00 1.00 523649
1 0.62 0.61 0.61 2012
accuracy 1.00 525661
macro avg 0.81 0.80 0.81 525661
weighted avg 1.00 1.00 1.00 525661실제 이상거래에서는 재현율을 비교하는 것이 좋다. 왜냐하면 2종오류와 관련이 있기 때문에 이상이 있는데 없다고 하면 피해가 커질 수 있기 때문이다.
여기까지 예측값은 0과 1로 나뉘었는데 기준점을 어디로 잡느냐에 따라서 예측 결과가 달라진다. 따라서 predict_proba를 사용하여 0과 1이 아닌 소수점 형태의 결과를 얻을 수 있다.
proba_1 = model_1.predict_proba(X_test)proba_1 = proba_1[:,1]1에 대한 결과만 저장해 준다.
proba_int1 = (proba_1>0.2).astype('int')
proba_int2 = (proba_1>0.8).astype('int')0.2와 0.8을 기준으로 혼동행렬과 분류리포트를 비교해 보겠다.
print(confusion_matrix(y_test, proba_int1))
print(confusion_matrix(y_test, proba_int2))
보면 0.8로 이동할 때 정밀도는 올라가지만 재현율은 떨어지는 것을 확인할 수 있다. 하지만 이것으로는 정확한 판단하기가 어렵다. 그래서 ROC곡선과 AUC라는 것을 활용해 보겠다.
roc_auc_score(y_test,proba_1)0.9491871968462691하이퍼파라미터 튜닝: 랜덤 그리드 서치
from sklearn.model_selection import RandomizedSearchCVparams = {
'n_estimators':[100,500,1000],
'learning_rate':[0.01,0.05,0.1,0.3],
'lambda_l1':[0,10,20,30,50],
'lambda_l2':[0,10,20,30,50],
'max_depth':[5,10,15,20],
'subsample':[0.6,0.8,1]
}여기서 lamda_l1, lambda_l2는 정규화로 기울기에 페널티를 부여하여 너무 큰 계수가 나오지 않도록 강제하는 방법이다.
l1정규화라쏘회귀는 불필요한 변수를 제거해 버리는 효과가 있고, l2 정규화는 모든 변수들이 모델에 반영된다.
model_2 = lgb.LGBMClassifier(random_state=100)
rs = RandomizedSearchCV(model_2, param_distributions=params, n_iter=30, scoring='roc_auc',random_state=100,n_jobs=-1)이번에는 roc_auc를 기준으로 모델을 만들어 줄 수 있다.
import time
start = time.time()
rs.fit(X_train,y_train)
print(time.time()-start)7574.391634464264훈련시간도 체크할 수 있다.
rs.best_params_
{'subsample': 1,
'n_estimators': 1000,
'max_depth': 15,
'learning_rate': 0.05,
'lambda_l2': 20,
'lambda_l1': 0}가장 좋은 파라미터를 출력해 주고
rs_proba = rs.predict_proba(X_test)
roc_auc_score(y_test, rs_proba[:,1])1 부분만 골라서, 점수를 출력해 준다.
0.9944612776469138rs_proba_int = (rs_proba[:,1]>0.2).astype('int')
print(confusion_matrix(y_test,rs_proba_int))[[522535 1114]
[ 580 1432]]print(classification_report(y_test, rs_proba_int))precision recall f1-score support
0 1.00 1.00 1.00 523649
1 0.56 0.71 0.63 2012
accuracy 1.00 525661
macro avg 0.78 0.85 0.81 525661
weighted avg 1.00 1.00 1.00 525661분류 점수와 혼동행렬도 0.2를 기준으로 구해본다.
LightGBM에서 train 함수 사용하기
train은 fit과 다르게 검증 셋을 지원하고, 데이터 프레임을 별도의 포맷으로 변환이 필요하고, 하이퍼파라미터를 꼭 지정해야 하며, 사이킷런과 연동이 불가하다.
train = data[data.index < '2020-01-01'] #훈련셋 설정
val = data[(data.index >= '2020-01-01')& (data.index<'2020-07-01')] #검증셋 검증
test = data[data.index >= '2020-07-01'] #시험셋 설정X_train = train.drop('is_fraud', axis=1)
X_val = val.drop('is_fraud', axis=1)
X_test = test.drop('is_fraud', axis=1)
y_train = train['is_fraud']
y_val = val['is_fraud']
y_test = test['is_fraud']독립변수와 종속변수를 분리해 줌
d_train = lgb.Dataset(X_train, label=y_train)
d_val = lgb.Dataset(X_val, label=y_val)DataSet을 통해 훈련 셋과 검증 셋에 대해서 고유한 데이터셋으로 변화시켜 준다.
params_set = rs.best_params_
params_set['metrics'] = 'auc'하이터파라미터를 지정해 준다.
params_set{'subsample': 1,
'n_estimators': 1000,
'max_depth': 15,
'learning_rate': 0.05,
'lambda_l2': 20,
'lambda_l1': 0,
'metrics': 'auc'}model_3 = lgb.train(params_set, d_train, valid_sets=[d_val], early_stopping_rounds=100, verbose_eval=100)파라미터 셋을 정한 것을 model_3로 만들어준다.
pred_3 = model_3.predict(X_test)예측변수를 만들고
roc_auc_score(y_test,pred_3)roc_auc_score(y_test,pred_3)
0.9892873466222063점수를 출력해 준다.
좀 전에 model_1과 model_3을 비교해 보겠다.
feature_imp = pd.DataFrame({'feature_name':X_train.columns, 'importance': model_1.feature_importances_}).sort_values('importance', ascending=False)
plt.figure(figsize=(20,10))
sns.barplot(x='importance', y='feature_name', data=feature_imp.head(10))
plt.show()feature_imp_3 = pd.DataFrame(sorted(zip(model_3.feature_importance(), X_train.columns)), columns=['Value', 'Feature'])
plt.figure(figsize=(20,10))
sns.barplot(x="importance",y="feature_name", data=feature_imp.head(10))
plt.show()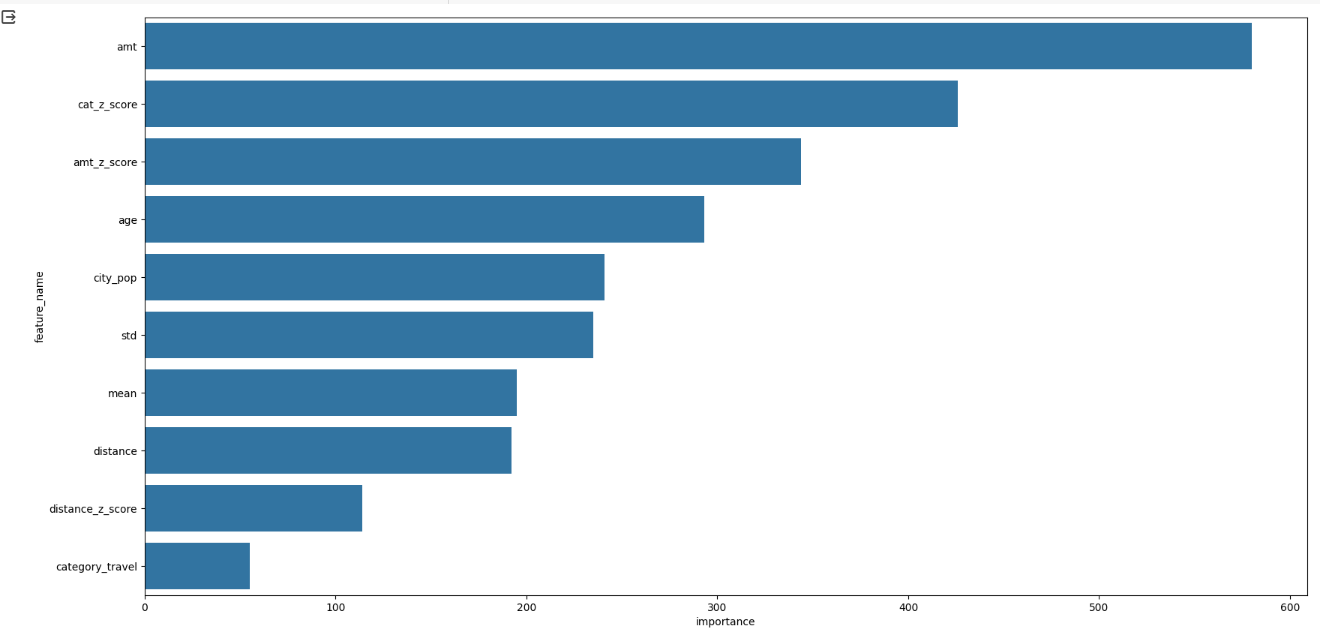
그래프상으로 육안상으로 비교할 수 없을 만큼 비슷하게 나와서 한 그래프만 출력하였다.

